1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
| from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
# 所有网络类要继承nn.Module
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__() # 调用父类构造函数
self.conv1 = nn.Conv2d(1, 20, 5, 1) # (in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
self.conv2 = nn.Conv2d(20, 50, 5, 1) # 这一层的in_channels正好是上一层的out_channels
self.fc1 = nn.Linear(4*4*50, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2) # kernel_size=2, stride=2,pooling之后的大小除以2
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4*4*50) # 展开成 (z, 4*4*50),其中z是通过自动推导得到的,所以这里设置为-1,这里相当于展开成行向量,便于后续全连接
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1) # log_softmax 即 log(softmax(x));dim=1对行进行softmax,因为上面x.view展开成行向量了,log_softmax速度和数值稳定性都比softmax好一些
def train(args, model, device, train_loader, optimizer, epoch):
model.train() # 告诉pytorch,这是训练阶段 https://stackoverflow.com/a/51433411/2468587
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # 每个batch的梯度重新累加
output = model(data)
loss = F.nll_loss(output, target) # 这里的nll_loss就是Michael Nielsen在ch3提到的log-likelihood cost function,配合softmax使用,batch的梯度/loss要求均值mean
loss.backward() # 求loss对参数的梯度dw
optimizer.step() # 梯度下降,w'=w-η*dw
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(args, model, device, test_loader):
model.eval() # 告诉pytorch,这是预测(评价)阶段
test_loss = 0
correct = 0
with torch.no_grad(): # 预测时不需要误差反传,https://discuss.pytorch.org/t/model-eval-vs-with-torch-no-grad/19615/2
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss,预测时的loss求sum,L54再求均值
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def plot1digit(data_loader):
import numpy as np
import matplotlib.pyplot as plt
examples = enumerate(data_loader)
batch_idx, (Xs, ys) = next(examples) # 读取到的是一个batch的所有数据
X=Xs[0].numpy()[0] # Xs[0]取出batch中的第一个数据,由tensor转换为numpy,因为pytorch tensor的格式是[channel, height, width],所以最后[0]取出其第一个通道的[h,w]
y=ys[0].numpy() # y没有通道,就一个标量值
np.savetxt('../../../fig/%d.csv'%y, X, delimiter=',')
plt.imshow(X, cmap='Greys') # or 'Greys_r'
plt.savefig('../../../fig/%d.png'%y)
plt.show()
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([ # https://discuss.pytorch.org/t/can-some-please-explain-how-the-transforms-work-and-why-normalize-the-data/2461/3
transforms.ToTensor(), # 把[0,255]的(H,W,C)的图片转换为[0,1]的(channel,height,width)的图片
transforms.Normalize((0.1307,), (0.3081,)) # 进行z-score标准化,这两个数分别是MNIST的均值和标准差
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
# plot1digit(train_loader)
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(args, model, device, test_loader)
if (args.save_model):
torch.save(model.state_dict(),"mnist_cnn.pt")
if __name__ == '__main__':
main()
|
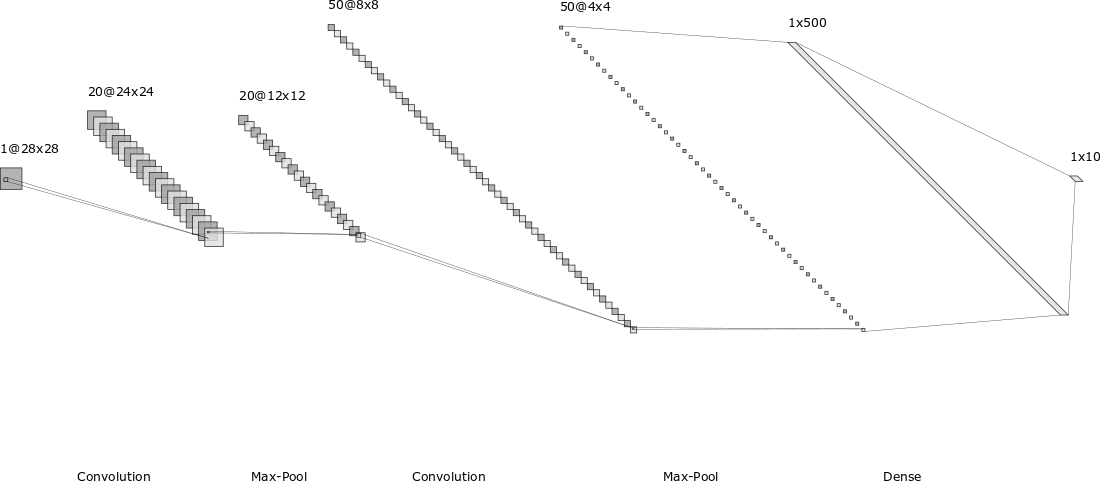 使用该工具在线制作:http://alexlenail.me/NN-SVG/LeNet.html
使用该工具在线制作:http://alexlenail.me/NN-SVG/LeNet.html