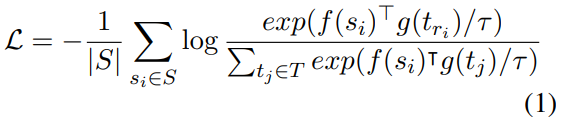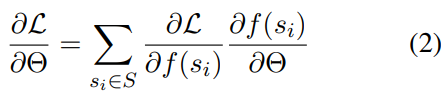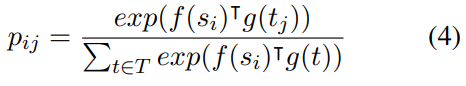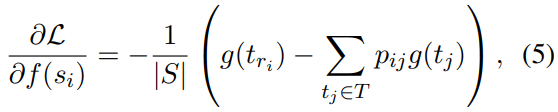1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
| from __future__ import annotations
from collections.abc import Iterable, Iterator
from contextlib import nullcontext
from functools import partial
from typing import Any
import torch
import tqdm
from torch import Tensor, nn
from torch.utils.checkpoint import get_device_states, set_device_states
from sentence_transformers import util
from sentence_transformers.models import StaticEmbedding
from sentence_transformers.SentenceTransformer import SentenceTransformer
from sentence_transformers.util import all_gather_with_grad
class RandContext:
"""
Random-state context manager class. Reference: https://github.com/luyug/GradCache.
This class will back up the pytorch's random state during initialization. Then when the context is activated,
the class will set up the random state with the backed-up one.
"""
def __init__(self, *tensors) -> None:
self.fwd_cpu_state = torch.get_rng_state()
self.fwd_gpu_devices, self.fwd_gpu_states = get_device_states(*tensors)
def __enter__(self) -> None:
self._fork = torch.random.fork_rng(devices=self.fwd_gpu_devices, enabled=True)
self._fork.__enter__()
torch.set_rng_state(self.fwd_cpu_state)
set_device_states(self.fwd_gpu_devices, self.fwd_gpu_states)
def __exit__(self, exc_type, exc_val, exc_tb) -> None:
self._fork.__exit__(exc_type, exc_val, exc_tb)
self._fork = None
def _backward_hook(
grad_output: Tensor,
sentence_features: Iterable[dict[str, Tensor]],
loss_obj: CachedMultipleNegativesRankingLoss,
) -> None:
"""A backward hook to backpropagate the cached gradients mini-batch by mini-batch."""
assert loss_obj.cache is not None
assert loss_obj.random_states is not None
with torch.enable_grad():
for sentence_feature, grad, random_states in zip(sentence_features, loss_obj.cache, loss_obj.random_states):
for (reps_mb, _), grad_mb in zip(
loss_obj.embed_minibatch_iter(
sentence_feature=sentence_feature,
with_grad=True,
copy_random_state=False,
random_states=random_states,
),
grad,
):
# TODO: This if-statement is for if the model does not require gradients, which may happen if the model
# contains a Router where one of the routes is frozen. It should be possible to not have to call
# embed_minibatch_iter in that case, as it's unnecessarily expensive.
if reps_mb.requires_grad:
surrogate = torch.dot(reps_mb.flatten(), grad_mb.flatten()) * grad_output
surrogate.backward()
class CachedMultipleNegativesRankingLoss(nn.Module):
def __init__(
self,
model: SentenceTransformer,
scale: float = 20.0,
similarity_fct: callable[[Tensor, Tensor], Tensor] = util.cos_sim,
mini_batch_size: int = 32,
gather_across_devices: bool = False,
show_progress_bar: bool = False,
) -> None:
"""
Boosted version of MultipleNegativesRankingLoss (https://huggingface.co/papers/1705.00652) by GradCache (https://huggingface.co/papers/2101.06983).
Constrastive learning (here our MNRL loss) with in-batch negatives is usually hard to work with large batch sizes due to (GPU) memory limitation.
Even with batch-scaling methods like gradient-scaling, it cannot work either. This is because the in-batch negatives make the data points within
the same batch non-independent and thus the batch cannot be broke down into mini-batches. GradCache is a smart way to solve this problem.
It achieves the goal by dividing the computation into two stages of embedding and loss calculation, which both can be scaled by mini-batches.
As a result, memory of constant size (e.g. that works with batch size = 32) can now process much larger batches (e.g. 65536).
In detail:
(1) It first does a quick embedding step without gradients/computation graphs to get all the embeddings;
(2) Calculate the loss, backward up to the embeddings and cache the gradients wrt. to the embeddings;
(3) A 2nd embedding step with gradients/computation graphs and connect the cached gradients into the backward chain.
Notes: All steps are done with mini-batches. In the original implementation of GradCache, (2) is not done in mini-batches and
requires a lot memory when the batch size is large. One drawback is about the speed. Gradient caching will sacrifice
around 20% computation time according to the paper.
Args:
model: SentenceTransformer model
scale: Output of similarity function is multiplied by scale value. In some literature, the scaling parameter
is referred to as temperature, which is the inverse of the scale. In short: scale = 1 / temperature, so
scale=20.0 is equivalent to temperature=0.05.
similarity_fct: similarity function between sentence embeddings. By default, cos_sim. Can also be set to dot
product (and then set scale to 1)
mini_batch_size: Mini-batch size for the forward pass, this denotes how much memory is actually used during
training and evaluation. The larger the mini-batch size, the more memory efficient the training is, but
the slower the training will be. It's recommended to set it as high as your GPU memory allows. The default
value is 32.
gather_across_devices: If True, gather the embeddings across all devices before computing the loss.
Recommended when training on multiple GPUs, as it allows for larger batch sizes, but it may slow down
training due to communication overhead, and can potentially lead to out-of-memory errors.
show_progress_bar: If True, a progress bar for the mini-batches is shown during training. The default is False.
References:
- Efficient Natural Language Response Suggestion for Smart Reply, Section 4.4: https://huggingface.co/papers/1705.00652
- Scaling Deep Contrastive Learning Batch Size under Memory Limited Setup: https://huggingface.co/papers/2101.06983
Requirements:
1. (anchor, positive) pairs or (anchor, positive, negative pairs)
2. Should be used with large `per_device_train_batch_size` and low `mini_batch_size` for superior performance, but slower training time than :class:`MultipleNegativesRankingLoss`.
Inputs:
+-------------------------------------------------+--------+
| Texts | Labels |
+=================================================+========+
| (anchor, positive) pairs | none |
+-------------------------------------------------+--------+
| (anchor, positive, negative) triplets | none |
+-------------------------------------------------+--------+
| (anchor, positive, negative_1, ..., negative_n) | none |
+-------------------------------------------------+--------+
Recommendations:
- Use ``BatchSamplers.NO_DUPLICATES`` (:class:`docs <sentence_transformers.training_args.BatchSamplers>`) to
ensure that no in-batch negatives are duplicates of the anchor or positive samples.
Relations:
- Equivalent to :class:`MultipleNegativesRankingLoss`, but with caching that allows for much higher batch sizes
(and thus better performance) without extra memory usage. This loss also trains roughly 2x to 2.4x slower than
:class:`MultipleNegativesRankingLoss`.
Example:
::
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses
from datasets import Dataset
model = SentenceTransformer("microsoft/mpnet-base")
train_dataset = Dataset.from_dict({
"anchor": ["It's nice weather outside today.", "He drove to work."],
"positive": ["It's so sunny.", "He took the car to the office."],
})
loss = losses.CachedMultipleNegativesRankingLoss(model, mini_batch_size=64)
trainer = SentenceTransformerTrainer(
model=model,
train_dataset=train_dataset,
loss=loss,
)
trainer.train()
"""
super().__init__()
if isinstance(model[0], StaticEmbedding):
raise ValueError(
"CachedMultipleNegativesRankingLoss is not compatible with a SentenceTransformer model based on a StaticEmbedding. "
"Consider using MultipleNegativesRankingLoss instead."
)
self.model = model
self.scale = scale
self.similarity_fct = similarity_fct
self.mini_batch_size = mini_batch_size
self.gather_across_devices = gather_across_devices
self.show_progress_bar = show_progress_bar
self.cross_entropy_loss = nn.CrossEntropyLoss()
self.cache: list[list[Tensor]] | None = None
self.random_states: list[list[RandContext]] | None = None
def embed_minibatch(
self,
sentence_feature: dict[str, Tensor],
begin: int,
end: int,
with_grad: bool,
copy_random_state: bool,
random_state: RandContext | None = None,
) -> tuple[Tensor, RandContext | None]:
"""Do forward pass on a minibatch of the input features and return corresponding embeddings."""
grad_context = nullcontext if with_grad else torch.no_grad
random_state_context = nullcontext() if random_state is None else random_state
sentence_feature_minibatch = {
key: value[begin:end] if isinstance(value, torch.Tensor) else value
for key, value in sentence_feature.items()
}
with random_state_context:
with grad_context():
random_state = RandContext(*sentence_feature_minibatch.values()) if copy_random_state else None
reps = self.model(sentence_feature_minibatch)["sentence_embedding"] # (mbsz, hdim)
return reps, random_state
def embed_minibatch_iter(
self,
sentence_feature: dict[str, Tensor],
with_grad: bool,
copy_random_state: bool,
random_states: list[RandContext] | None = None,
) -> Iterator[tuple[Tensor, RandContext | None]]:
"""Do forward pass on all the minibatches of the input features and yield corresponding embeddings."""
input_ids: Tensor = sentence_feature["input_ids"]
bsz, _ = input_ids.shape
for i, b in enumerate(
tqdm.trange(
0,
bsz,
self.mini_batch_size,
desc="Embed mini-batches",
disable=not self.show_progress_bar,
)
):
e = b + self.mini_batch_size
reps, random_state = self.embed_minibatch(
sentence_feature=sentence_feature,
begin=b,
end=e,
with_grad=with_grad,
copy_random_state=copy_random_state,
random_state=None if random_states is None else random_states[i],
)
yield reps, random_state # reps: (mbsz, hdim)
def calculate_loss_and_cache_gradients(self, reps: list[list[Tensor]]) -> Tensor:
"""Calculate the cross-entropy loss and cache the gradients wrt. the embeddings."""
loss = self.calculate_loss(reps, with_backward=True)
loss = loss.detach().requires_grad_()
self.cache = [[r.grad for r in rs] for rs in reps] # e.g. 3 * bsz/mbsz * (mbsz, hdim)
return loss
def calculate_loss(self, reps: list[list[Tensor]], with_backward: bool = False) -> Tensor:
"""Calculate the cross-entropy loss. No need to cache the gradients."""
anchors = torch.cat(reps[0]) # (batch_size, embedding_dim)
candidates = [torch.cat(r) for r in reps[1:]] # (1 + num_neg) tensors of shape (batch_size, embedding_dim)
batch_size = len(anchors)
offset = 0
if self.gather_across_devices:
# Gather the positives and negatives across all devices, with gradients, but not the anchors. We compute
# only this device's anchors with all candidates from all devices, such that the backward pass on the document
# embeddings can flow back to the original devices.
candidates = [all_gather_with_grad(embedding_column) for embedding_column in candidates]
# (1 + num_negatives) tensors of shape (batch_size * world_size, embedding_dim)
# Adjust the range_labels to account for the gathered candidates
if torch.distributed.is_initialized():
rank = torch.distributed.get_rank()
offset = rank * batch_size
candidates = torch.cat(candidates, dim=0)
# (batch_size * world_size * (1 + num_negatives), embedding_dim)
# anchor[i] should be most similar to candidates[i], as that is the paired positive,
# so the label for anchor[i] is i, but adjusted for the rank offset if gathered across devices
labels = torch.arange(offset, offset + batch_size, device=anchors.device)
losses: list[torch.Tensor] = []
for b in tqdm.trange(
0,
batch_size,
self.mini_batch_size,
desc="Preparing caches",
disable=not self.show_progress_bar,
):
e = b + self.mini_batch_size
scores: Tensor = self.similarity_fct(anchors[b:e], candidates) * self.scale
loss_mbatch: torch.Tensor = self.cross_entropy_loss(scores, labels[b:e]) * len(scores) / batch_size
if with_backward:
loss_mbatch.backward()
loss_mbatch = loss_mbatch.detach()
losses.append(loss_mbatch)
loss = sum(losses)
return loss
def forward(self, sentence_features: Iterable[dict[str, Tensor]], labels: Tensor) -> Tensor:
# Step (1): A quick embedding step without gradients/computation graphs to get all the embeddings
reps = []
self.random_states = [] # Copy random states to guarantee exact reproduction of the embeddings during the second forward pass, i.e. step (3)
for sentence_feature in sentence_features:
reps_mbs = []
random_state_mbs = []
for reps_mb, random_state in self.embed_minibatch_iter(
sentence_feature=sentence_feature,
with_grad=False,
copy_random_state=True,
):
reps_mbs.append(reps_mb.detach().requires_grad_())
random_state_mbs.append(random_state)
reps.append(reps_mbs)
self.random_states.append(random_state_mbs)
if torch.is_grad_enabled():
# Step (2): Calculate the loss, backward up to the embeddings and cache the gradients wrt. to the embeddings
loss = self.calculate_loss_and_cache_gradients(reps)
# Step (3): A 2nd embedding step with gradients/computation graphs and connect the cached gradients into the backward chain
loss.register_hook(partial(_backward_hook, sentence_features=sentence_features, loss_obj=self))
else:
# If grad is not enabled (e.g. in evaluation), then we don't have to worry about the gradients or backward hook
loss = self.calculate_loss(reps)
return loss
def get_config_dict(self) -> dict[str, Any]:
return {
"scale": self.scale,
"similarity_fct": self.similarity_fct.__name__,
"mini_batch_size": self.mini_batch_size,
"gather_across_devices": self.gather_across_devices,
}
@property
def citation(self) -> str:
return """
@misc{gao2021scaling,
title={Scaling Deep Contrastive Learning Batch Size under Memory Limited Setup},
author={Luyu Gao and Yunyi Zhang and Jiawei Han and Jamie Callan},
year={2021},
eprint={2101.06983},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
"""
|