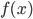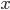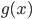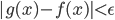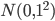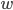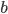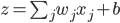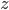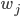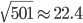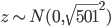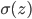本章我们将分析一下为什么深度神经网络难以训练的问题。
首先来看问题:如果神经网络的层次不断加深,则在BP误差反向传播的过程中,网络前几层的梯度更新会非常慢,导致前几层的权重无法学习到比较好的值,这就是梯度消失问题(The vanishing gradient problem)。
以我们在第三章学习的network2.py为例(交叉熵损失函数+Sigmoid激活函数),我们可以计算每个神经元中误差对偏移量$b$的偏导$\partial C/ \partial b$,根据第二章BP网络的知识,$\partial C/ \partial b$也是$\partial C/ \partial w$的一部分(BP3和BP4的关系),所以如果$\partial C/ \partial b$的绝对值大,则说明梯度大,在误差反向传播的时候,$b$和$w$更新就快。