今天开始介绍大名鼎鼎的NLP网课Stanford-CS224N。第一讲内容为课程简介和词向量。
词向量即用来表示这个词的含义的向量。早期的NLP常用one-hot编码来表示词向量,假如词典中共有10000个词,则这个one-hot向量长度就是10000,该词在词典中所处位置对应的值为1,其他值为0。
one-hot表示方法虽然简单,但其有诸多缺点:1. 词典中的词是不断增多的,比如英语,通过对原有的词增加前缀和后缀,可以变换出很多不同的词,one-hot编码会导致向量维度非常大,且每个向量是稀疏的;2. 不同词的one-hot编码向量是垂直的,在向量空间中无法表示近似关系,即使两个含义相近的词,它们的词向量点积也为0。
既然one-hot编码有这么多缺点,那我们就换一种编码,one-hot是高维稀疏向量,那新的编码就改用低维稠密向量,这样就解决了上述问题,那么怎样得到一个词的低维稠密的词向量呢?这就是word2vec算法。
word2vec采用了分布式语义的方法来表示一个词的含义。本质上,一个词的含义就是这个词所处的上下文语境。回想一下我们高中做英语完形填空时,一篇短文,挖了好多空,让我们根据空缺词的上下文语境选择合适的词。也就是说上下文语境已经能够确定这个词的含义了,如果选词正确,也就意味着我们理解了这个空缺词的含义。
word2vec算法发表于2013年,包括两种训练算法Skip-grams (SG)和Continuous Bag of Words (CBOW),这两种方法很类似,其中CBOW和上述介绍到的英语完形填空几乎是一样的,由上下文词预测中心词;而SG则和CBOW正好相反,由中心词预测上下文词,本文主要介绍SG算法。
给定一个语料库,这个语料库包含了很多文章,每篇文章又包含很多句子,每个句子又包含很多词语。所以一个语料库是一个天然的标注集,因为对于每一个选定的中心词,我们都知道其临近的词是什么。这样一个(中心词,临近词)对就构成了一个标注集。SG算法的中心思想就是对于每个选定的中心词,尽量准确的预测其周围可能出现的词的概率分布。具体来说,SG算法首先随机初始化每个词的词向量;然后预测不同临近词出现的概率,最后最大化实际临近词出现的概率。
形式化来说,就是用极大似然估计的方法,求解每个词的词向量。其目标函数如下,其中$\theta$是待求解的参数;$t$为选定的中心词位置;对于每个$t$(外层$\prod$),估计其邻域$\pm m$个词出现的概率(内层$\prod$)。

求解极大似然估计的方法比较成熟,一般先把极大似然转换为最小化-log似然,然后用梯度下降求解。所以核心问题就变成了如何求解$P(w_{t+j}|w_t;\theta)$。
对于每个词$w$,定义其两个词向量:$v_w$表示当$w$为中心词时的词向量,$u_w$表示当$w$为其他词的临近词时的词向量。则对于一个中心词$c$和其临近词$o$,有:

上式本质是一个softmax函数,因为给定$c$,$o$相当于是标注结果,所以把它们的点积作为分子,希望分子越大越好;而分母则是所有可能的$u_w$和$v_c$的点积之和,起到归一化作用。
题外话:讲这张幻灯片时,还提到softmax的一个形象解释。softmax包括max和soft两层含义。假设对于一个数组[1,2,3,4],直接max也就是hard max的结果是保留最大值,其他全变为0,即[0,0,0,4]。但是softmax对他们求$\frac{exp(x_i)}{\sum_{j=1}^nexp(x_j)}$,变成了[0.03, 0.09, 0.24, 0.64],最大的还是第4个数,但第四个数的优势被放大了,原来4只是1的4倍,现在0.64是0.03的21倍。所以softmax不但保留了max的属性,还变得更soft了,原来小的数不会被抹为0,只不过拉大了差异。
使用梯度下降还需要求解$P$对参数$\theta$的梯度,在这里$\theta$代表了所有词的中心词向量和临近词向量。对于上式,$u_o$、$v_c$等就是$\theta$的一部分。不断利用求导的链式法则,容易得到:
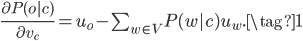
最后算出来的梯度很有意思,$u_o$表示观察到的上下文词向量(o表示observed),减号后面的是这个位置的期望的词向量,期望=概率*值。差值就是真实观察词向量减去期望词向量,这就是梯度。当它们的差值很小时,说明给定$c$能很好的预测其临近词的概率分布。
OK,当以上内容都准备妥当之后,我们就可以开始求解词向量了。首先随机初始化每个词$w$的中心词向量$v_w$和临近词向量$u_w$;然后求解-log损失函数$J(\theta)$;最后根据梯度下降更新所有参数$\theta$。
上述word2vec算法简单,直观,但写代码实现比较复杂。在实际应用场景中,人们往往使用神经网络的方法来求解词向量,具体教程请看这里: http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/ 。
我们把训练词向量的问题转换为端到端的文本分类问题。如下图所示,对于语料库中的一个句子,假设临近窗口为前后两个词,则可以抽取出如下图右边所示的训练样本,每个训练样本是一个(中心词,临近词)的pair。比如对于(the, quick)训练样本,我们希望神经网络在输入the这个中心词时,能以较高的概率预测出quick这个词。

网络的结构如下图所示,也非常简单,是仅含一个隐藏层的全连接网络。比如上图的一组训练数据是(the, quick),表示输入是the的one-hot编码,输出是quick的one-hot编码。假设词典里有10,000个不同的词,则one-hot编码长度为10,000。有一个隐藏层的全连接网络,对应权重构成两个权重矩阵,和输入层连接的矩阵为$V$,其每一行表示词作为中心词时的词向量。输入行向量乘以$V$正好得到输入词的词向量,这对应课上讲的作为中心词的词向量$v_c$。
隐层和输出层连接的权重矩阵为$U$,其每一列表示输出层的词的临近词词向量。隐层的行向量$v_c$乘以矩阵$U$,得到词$c$的临近词的概率分布,再经过softmax激活,进行归一化。其实反过来看,从输出往隐层看,相当于输出层的行向量乘以$U$的转置,得到隐层词向量。这其实就是另一种训练词向量的方法CBOW,即英语完形填空,用临近词来预测中心词。
对于下图的神经网络,输出用softmax激活,损失函数使用-log损失,训练网络时使用梯度下降,其效果正好是课上讲的使用极大似然估计的方法!

另一方面,上图的这种结构是skip-gram模型,如果把对应的箭头反一下,输入变输出,输出变输入,其实就变成了CBOW模型了。
上述全连接网络虽然能很方便的计算词向量,但存在两个问题:1. 网络过于庞大,参数量太多;2. 训练样本太多,每个样本都更新所有参数,训练速度慢。针对这两个问题,作者分别提出了 subsampling 和 negative sampling 的技巧,具体请看教程:
http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/ 。
第一个问题,网络参数量太多。假设有1w个特异的词,词向量长度为300,整个网络就有两个300w的矩阵(上图的V和U)参数需要优化。另一方面,训练语料库往往是很大的,随随便便就是成百上千万的文章,由此拆分得到的训练词组对就更大了,很容易到上亿的级别。几百万的参数,几亿的训练数据, 导致网络太过庞大,训练不动。
subsampling技巧是指,每个词有一个保留概率p,以这个概率p保留其在训练数据中,以1-p删掉这个词。比如上面的例子,删掉了fox,则fox对应的4个训练数据也一并删掉了,所以能减少较多的训练数据。对于词$w_i$,其概率$P(w_i)$公式如下,其中$z(w_i)$是词$w$的词频。概率p和这个词在语料库中的词频有关,词频越大,保留概率越低,即被删掉的概率越大,所以subsampling之后应该能较大的减少训练数据。
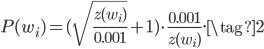
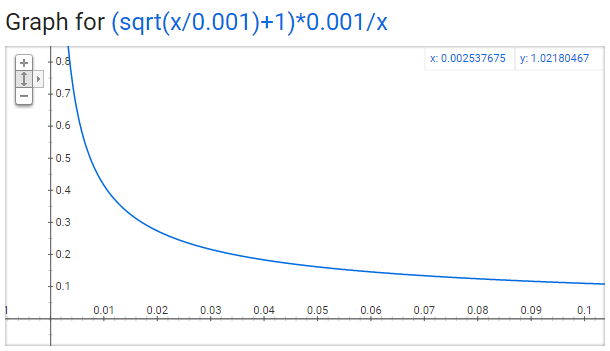
第二个问题,原来的网络在训练时,对于每个输入中心词,都会对两个很大的参数矩阵V和U(和上面假设一样,300w)进行轻微的更新,更新操作太多了。
negative sampling技巧,只更新一小部分参数。比如对于(“fox”, “quick”),期望的输出是quick的one-hot,即只有quick对应位为1,其他为0。但网络的softmax输出肯定不可能是完完全全的quick为1,其他为0;有可能是quick为0.8,其他位有些0.001,0.03之类的非0值,这就导致输出层的所有神经元都有误差。按照传统的方法,输出层所有神经元对应的U矩阵的权重都要更新。negative sampling技巧是,只更新和quick连接的U权重以及随机选5个输出神经元的连接权重进行更新,这样一下把需要更新的U权重个数从300w降到了6*300=1800,只需要更新0.06%的参数,大大减小了参数更新量!
5个随机选中的神经元(输出位置,即对应1w维的某个词)被称为negative sample,被选中的概率和词频成正比,词频越大的词被选中的概率越大,和上面subsampling类似。概率公式如下,其中$f(w_i)$应该和(2)中的$z(w_i)$一样,都表示词频。
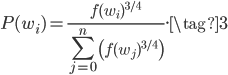
复习SVD分解请看:
https://blog.csdn.net/u010099080/article/details/68060274 以及
https://www.zhihu.com/question/34143886/answer/131046490
Pingback: CS224N(2.19)Contextual Word Embeddings | bitJoy