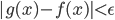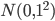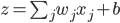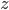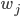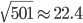今天开始介绍大名鼎鼎的NLP网课Stanford-CS224N。第一讲内容为课程简介和词向量。
词向量即用来表示这个词的含义的向量。早期的NLP常用one-hot编码来表示词向量,假如词典中共有10000个词,则这个one-hot向量长度就是10000,该词在词典中所处位置对应的值为1,其他值为0。
one-hot表示方法虽然简单,但其有诸多缺点:1. 词典中的词是不断增多的,比如英语,通过对原有的词增加前缀和后缀,可以变换出很多不同的词,one-hot编码会导致向量维度非常大,且每个向量是稀疏的;2. 不同词的one-hot编码向量是垂直的,在向量空间中无法表示近似关系,即使两个含义相近的词,它们的词向量点积也为0。
既然one-hot编码有这么多缺点,那我们就换一种编码,one-hot是高维稀疏向量,那新的编码就改用低维稠密向量,这样就解决了上述问题,那么怎样得到一个词的低维稠密的词向量呢?这就是word2vec算法。
Continue reading