由于本书成书较早(2015),作者当时使用的是Theano,但Theano已不再维护,所以本博客使用当下流行的Pytorch框架讲解MNIST图片分类的代码实现,具体就是Pytorch官方给出的MNIST代码:
https://github.com/pytorch/examples/tree/master/mnist。
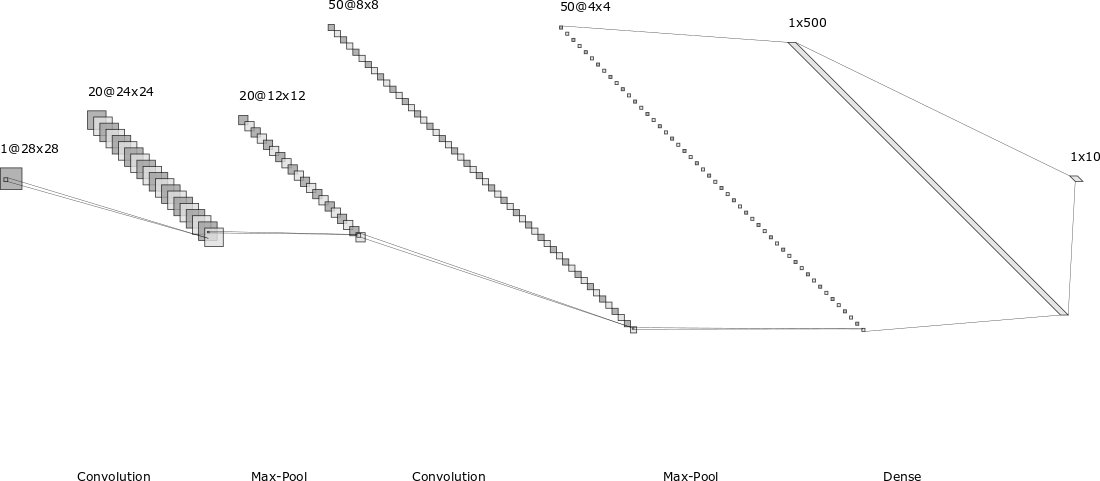
http://alexlenail.me/NN-SVG/LeNet.html
下面,我首先贴出经过我注释的Pytorch MNIST代码,然后对一些关键问题进行解释。
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
# 所有网络类要继承nn.Module
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__() # 调用父类构造函数
self.conv1 = nn.Conv2d(1, 20, 5, 1) # (in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
self.conv2 = nn.Conv2d(20, 50, 5, 1) # 这一层的in_channels正好是上一层的out_channels
self.fc1 = nn.Linear(4*4*50, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2) # kernel_size=2, stride=2,pooling之后的大小除以2
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4*4*50) # 展开成 (z, 4*4*50),其中z是通过自动推导得到的,所以这里设置为-1,这里相当于展开成行向量,便于后续全连接
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1) # log_softmax 即 log(softmax(x));dim=1对行进行softmax,因为上面x.view展开成行向量了,log_softmax速度和数值稳定性都比softmax好一些
def train(args, model, device, train_loader, optimizer, epoch):
model.train() # 告诉pytorch,这是训练阶段 https://stackoverflow.com/a/51433411/2468587
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # 每个batch的梯度重新累加
output = model(data)
loss = F.nll_loss(output, target) # 这里的nll_loss就是Michael Nielsen在ch3提到的log-likelihood cost function,配合softmax使用,batch的梯度/loss要求均值mean
loss.backward() # 求loss对参数的梯度dw
optimizer.step() # 梯度下降,w'=w-η*dw
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(args, model, device, test_loader):
model.eval() # 告诉pytorch,这是预测(评价)阶段
test_loss = 0
correct = 0
with torch.no_grad(): # 预测时不需要误差反传,https://discuss.pytorch.org/t/model-eval-vs-with-torch-no-grad/19615/2
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss,预测时的loss求sum,L54再求均值
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def plot1digit(data_loader):
import numpy as np
import matplotlib.pyplot as plt
examples = enumerate(data_loader)
batch_idx, (Xs, ys) = next(examples) # 读取到的是一个batch的所有数据
X=Xs[0].numpy()[0] # Xs[0]取出batch中的第一个数据,由tensor转换为numpy,因为pytorch tensor的格式是[channel, height, width],所以最后[0]取出其第一个通道的[h,w]
y=ys[0].numpy() # y没有通道,就一个标量值
np.savetxt('../../../fig/%d.csv'%y, X, delimiter=',')
plt.imshow(X, cmap='Greys') # or 'Greys_r'
plt.savefig('../../../fig/%d.png'%y)
plt.show()
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([ # https://discuss.pytorch.org/t/can-some-please-explain-how-the-transforms-work-and-why-normalize-the-data/2461/3
transforms.ToTensor(), # 把[0,255]的(H,W,C)的图片转换为[0,1]的(channel,height,width)的图片
transforms.Normalize((0.1307,), (0.3081,)) # 进行z-score标准化,这两个数分别是MNIST的均值和标准差
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
# plot1digit(train_loader)
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(args, model, device, test_loader)
if (args.save_model):
torch.save(model.state_dict(),"mnist_cnn.pt")
if __name__ == '__main__':
main()
首先是MNIST数据格式的问题,在L108~L120,我们使用Pytorch的DataLoader载入了训练和测试数据,数据格式本质上和本系列博客的第一篇博客介绍的是一致的,即每张图片都是28*28的灰度图片,因为是灰度图片,所以只有一个通道数,默认格式是(H,W,C),且值域范围是[0,255]。但上述代码对原始图片进行了两个变换,分别是ToTensor和Normalize。ToTensor将[0,255]的灰度图片(H,W,C)转换为[0,1]的灰度图片(C,H,W),即Pytorch对2D图片的格式要求都是channel在前。所以经过这一转换,一张图片的shape是(1,28,28),是一个三维矩阵;如果是彩色图片的话,有R,G,B三个通道,C=3。Normalize对图片数据进行z-score标准化,即减去均值再除以标准差;L112的两个值就是预先计算的MNIST数据集的均值和标准差。这些操作的好处是能让模型更加平稳快速收敛。同第一篇博客一样,我们可以把Pytorch格式的图片打印出来以便直观理解,L61的plot1digit函数就是这个作用。
Pytorch中自定义的网络类都要继承nn.Module这个基类(L10),自定义的网络类需要实现两个函数,分别是构造函数__init__和前向传播函数forward。在__init__中,定义需要用到的成员变量,往往是一些layer,比如上述代码中定义了两个卷积层和两个全连接层。在forward中,完成了实际的网络搭建过程,传入图片x,x流过整个网络,最后返回网络的输出。
上述代码的网络结构如本博客开篇的图片所示,依次是:输入层、卷积层(包含ReLU激活)、池化层、卷积层(包含ReLU激活)、池化层、全连接层(包含ReLU激活)、全连接层(包含logsoftmax输出)。网络的构建过程很像搭积木,在forward函数和开篇的图片中都能很直观的看出来。
需要稍微解释一下的是Conv2d类的初始化参数,前4个参数分别是in_channels, out_channels, kernel_size, stride,分别表示传入通道数、传出通道数、卷积核大小、卷积步长,对于第一个卷积核(L13),由于直接和输入层相连,MNIST图片是28*28的单通道图片,所以in_channels=1;out_channels的大小表示所用卷积核的数目,比如这里设置为20就表示有20个卷积核;kernel_size=5表示5*5的卷积核;stride=1表示卷积移动的步长为1。(1,28,28)的图片,经过上述卷积之后,得到的feature map大小变为了(20,24,24),即有20个大小为24*24的feature map。经过max_pooling之后变为(20,12,12),只改变了feature map大小,没有改变其channels数。所以第二个卷积核的in_channels等于第一个卷积核的out_channels,等于20(L14)。以此类推,第二个max_pooling输出的feature map就是(50,4,4),所以第一个全连接层的输入维度是4*4*50。需要稍微注意的是在由feature map和下一层进行全连接时,需要先展开成一个行向量(L23),变成类似于BP网络的输入格式。
Pytorch的官方文档对每个函数都有详细的解释,甚至还给出了公式说明怎样计算卷积层和池化层之后的feature map的size,非常良心,所以遇到任何问题,一定要先仔细看官方文档。如果你仔细看文档的话,会发现nn和nn.functional下会有很多同名的类和函数,比如nn.Conv2d和nn.functional.conv2d同时存在,有关它们的区别,简单来说,前者表示类,后者表示函数,像卷积层、全连接层等需要保存学习参数的layer,建议使用nn;而像ReLU和max_pooling等不需要保存学习参数或功能比较简单的layer,建议直接用nn.functional,具体的区别和建议请看:https://www.zhihu.com/question/66782101/answer/579393790。
其他还有一些小细节,比如Pytorch模型在训练和预测时,需要分别调用model.train()和model.eval()告诉Pytorch此时是训练和预测阶段了,因为在train阶段,会使用dropout、batchnorm等技术,而在预测时不会调用,所以需要显式告诉Pytorch现在是训练还是预测。还有就是训练阶段,每个batch需要梯度清零(optimizer.zero_grad)、求梯度(loss.backward)、梯度下降更新参数(optimizer.step)等步骤。在预测阶段,不用求梯度(torch.no_grad)等。具体可以看上述代码注释。
最后总结,使用Pytorch构建深度学习模型是非常简单的,注意Pytorch的基本规则,仿照MNIST例子依葫芦画瓢就可以搭建自己的模型了。建议大家看过官方代码之后,自己重写一遍,检查一下是否学习到位。
至此,Neural Networks and Deep Learning这本书的学习笔记到此结束,算是入门了神经网络和深度学习,接下来请开启深度学习实战的炼丹之旅。