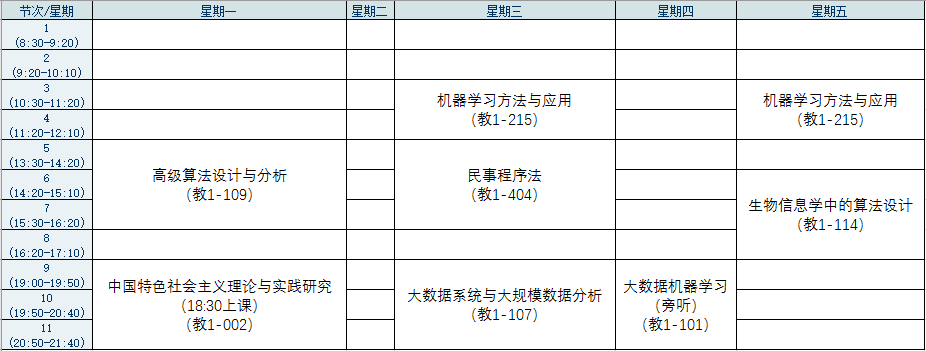
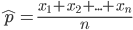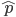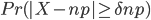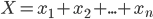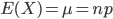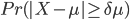上一回介绍了HMM的解码问题,今天我们介绍HMM的学习问题和识别问题,先来看学习问题。
正如上一回结束时所说,HMM的学习问题是:仅已知观测序列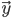 ,要估计出模型参数组
,要估计出模型参数组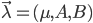 ,其中
,其中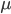 为初始概率分布向量,
为初始概率分布向量,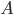 为转移概率矩阵,
为转移概率矩阵,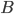 为发射概率矩阵。
为发射概率矩阵。
算法设计
求解HMM的参数学习问题,就是求解如下的最优化问题:
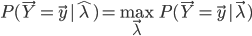
也就是找一个参数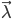 ,使得模型在该参数下最有可能产生当前的观测。如果使用极大似然法求解,对于似然函数
,使得模型在该参数下最有可能产生当前的观测。如果使用极大似然法求解,对于似然函数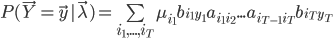 而言,这个最大值问题的计算量过大,在实际中是不可能被采用的。为此,人们构造了一个递推算法,使其能相当合理地给出模型参数的粗略估计。其核心思想是:并不要求备选
而言,这个最大值问题的计算量过大,在实际中是不可能被采用的。为此,人们构造了一个递推算法,使其能相当合理地给出模型参数的粗略估计。其核心思想是:并不要求备选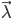 使得
使得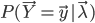 达到最大或局部极大,而只要求使相当大,从而使计算变为实际可能。 Continue reading
达到最大或局部极大,而只要求使相当大,从而使计算变为实际可能。 Continue reading