梯度消失
今天介绍RNN的梯度消失问题以及为了解决这个问题引出的RNN变种,如LSTM何GRU。
在上一篇博客中,通过公式推导,我们已经解释了RNN为什么容易产生梯度消失或梯度爆炸的问题,核心问题就是RNN在不同时间步使用共享参数$W$,导致$t+n$时刻的损失对$t$时刻的参数的偏导数存在$W$的指数形式,一旦$W$很小或很大就会导致梯度消失或梯度爆炸的问题。下图形象的显示了梯度消失的问题,即梯度不断反传,梯度不断变小(箭头不断变小)。

梯度消失
今天介绍RNN的梯度消失问题以及为了解决这个问题引出的RNN变种,如LSTM何GRU。
在上一篇博客中,通过公式推导,我们已经解释了RNN为什么容易产生梯度消失或梯度爆炸的问题,核心问题就是RNN在不同时间步使用共享参数$W$,导致$t+n$时刻的损失对$t$时刻的参数的偏导数存在$W$的指数形式,一旦$W$很小或很大就会导致梯度消失或梯度爆炸的问题。下图形象的显示了梯度消失的问题,即梯度不断反传,梯度不断变小(箭头不断变小)。
今天要介绍一个新的NLP任务——语言模型(Language Modeling, LM),以及用来训练语言模型的一类新的神经网络——循环神经网络(Recurrent Neural Networks, RNNs)。
语言模型就是预测一个句子中下一个词的概率分布。如下图所示,假设给定一个句子前缀是the students opened their,语言模型预测这个句子片段下一个词是books、laptops、exams、minds或者其他任意一个词的概率。形式化表示就是计算概率
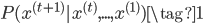
$x^{(t+1)}$表示第$t+1$个位置(时刻)的词是$x$,$x$可以是词典$V$中的任意一个词。

这篇博客把1.15和1.17两次课内容合并到一起,因为两次课的内容都是BP及公式推导,和之前的Neural Networks and Deep Learning(二)BP网络内容基本相同,这里不再赘述。下面主要列一些需要注意的知识点。
使用神经网络进行表示学习,不用输入的x直接预测输出,而是加一个中间层(图中橙色神经元),让中间层对输入层做一定的变换,然后中间层负责预测输出是什么。那么中间层能学到输入层的特征,相当于表示学习,自动学习特征。对于word2vec,中间层就是词向量。

这一讲介绍误差反向传播(backpropagation)网络,简称BP网络。
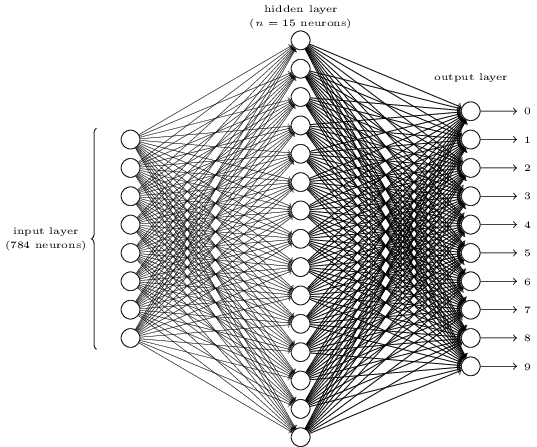
以上一讲介绍的MNIST手写数字图片分类问题为研究对象,首先明确输入输出:输入就是一张28×28的手写数字图片,展开后可以表示成一个长度为784的向量;输出可以表示为一个长度为10的one-hot向量,比如输入是一张“3”的图片,则输出向量为(0,0,0,1,0,0,0,0,0,0,0)。
然后构造一个如下的三层全连接网络。第一层为输入层,包含784个神经元,正好对应输入的一张28×28的图片。第二层为隐藏层,假设隐藏层有15个神经元。第三层为输出层,正好10个神经元,对应该图片的one-hot结果。
全连接网络表示上一层的每个神经元都和下一层的每个神经元有连接,即每个神经元的输入来自上一层所有神经元的输出,每个神经元的输出连接到下一层的所有神经元。每条连边上都有一个权重w。