构建好倒排索引之后,就可以开始检索了。
检索模型有很多,比如向量空间模型、概率模型、语言模型等。其中最有名的、检索效果最好的是基于概率的BM25模型。
给定一个查询Q和一篇文档d,d对Q的BM25得分公式为
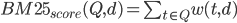
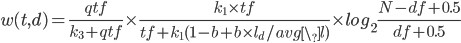
公式中变量含义如下:
- $qtf$:查询中的词频
- $tf$:文档中的词频
- $l_d$:文档长度
- $avg\_l$:平均文档长度
- $N$:文档数量
- $df$:文档频率
- $b,k_1,k_3$:可调参数
这个公式看起来很复杂,我们把它分解一下,其实很容易理解。第一个公式是外部公式,一个查询Q可能包含多个词项,比如“苹果手机”就包含“苹果”和“手机”两个词项,我们需要分别计算“苹果”和“手机”对某个文档d的贡献分数w(t,d),然后将他们加起来就是整个文档d相对于查询Q的得分。
第二个公式就是计算某个词项t在文档d中的得分,它包括三个部分。第一个部分是词项t在查询Q中的得分,比如查询“中国人说中国话”中“中国”出现了两次,此时qtf=2,说明这个查询希望找到的文档和“中国”更相关,“中国”的权重应该更大,但是通常情况下,查询Q都很短,而且不太可能包含相同的词项,所以这个因子是一个常数,我们在实现的时候可以忽略。
第二部分类似于TFIDF模型中的TF项。也就是说某个词项t在文档d中出现次数越多,则t越重要,但是文档长度越长,tf也倾向于变大,所以使用文档长度除以平均长度$l_d/avg\_l$起到某种归一化的效果,$k_1$和$b$是可调参数。
第三部分类似于TFIDF模型中的IDF项。也就是说虽然“的”、“地”、“得”等停用词在某文档d中出现的次数很多,但是他们在很多文档中都出现过,所以这些词对d的贡献分并不高,接近于0;反而那些很稀有的词如”糖尿病“能够很好的区分不同文档,这些词对文档的贡献分应该较高。
所以根据BM25公式,我们可以很快计算出不同文档t对查询Q的得分情况,然后按得分高低排序给出结果。
下面是给定一个查询句子sentence,根据BM25公式给出文档排名的函数
def result_by_BM25(self, sentence):
seg_list = jieba.lcut(sentence, cut_all=False)
n, cleaned_dict = self.clean_list(seg_list)
BM25_scores = {}
for term in cleaned_dict.keys():
r = self.fetch_from_db(term)
if r is None:
continue
df = r[1]
w = math.log2((self.N - df + 0.5) / (df + 0.5))
docs = r[2].split('\n')
for doc in docs:
docid, date_time, tf, ld = doc.split('\t')
docid = int(docid)
tf = int(tf)
ld = int(ld)
s = (self.K1 * tf * w) / (tf + self.K1 * (1 - self.B + self.B * ld / self.AVG_L))
if docid in BM25_scores:
BM25_scores[docid] = BM25_scores[docid] + s
else:
BM25_scores[docid] = s
BM25_scores = sorted(BM25_scores.items(), key = operator.itemgetter(1))
BM25_scores.reverse()
if len(BM25_scores) == 0:
return 0, []
else:
return 1, BM25_scores
首先将句子分词得到所有查询词项,然后从数据库中取出词项对应的倒排记录表,对记录表中的所有文档,计算其BM25得分,最后按得分高低排序作为查询结果。
类似的,我们还可以对所有文档按时间先后顺序排序,越新鲜的新闻排名越高;还可以按新闻的热度排序,越热门的新闻排名越高。
关于热度公式,我们认为一方面要兼顾相关度,另一方面也要考虑时间因素,所以是BM25打分和时间打分的一个综合。
比较有名的热度公式有两个,一个是Hacker News的,另一个是Reddit的,他们的公式分别为:
![图1. hacker news ranking algorithm [1]](https://bitjoy-1255847119.cos.ap-beijing.myqcloud.com/blog/2016/01/hacker-news-ranking-algo.png)
![图2. reddit ranking algorithm [2]](https://bitjoy-1255847119.cos.ap-beijing.myqcloud.com/blog/2016/01/reddit-ranking-algo.png)
可以看出,他们都是将新闻/评论的一个原始得分和时间组合起来,只是一个用除法,一个用加法。所以我们也依葫芦画瓢,”自创“了一个简单的热度公式:
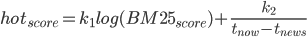
用BM25得分加上新闻时间和当前时间的差值的倒数,$k_1$和$k_2$也是可调参数。
按时间排序和按热度排序的函数和按BM25打分排序的函数类似,这里就不贴出来了,详细情况可以看我的Github项目News_IR_Demo。
至此,搜索引擎的搜索功能已经实现了,你可以试着修改./web/search_engine.py的第167行的关键词,看看搜索结果是否和你预想的排序是一样的。不过由于我们的数据量只有1000个新闻,并不能涵盖所有关键词,更多的测试可以留给大家线下完成。
[1]. http://amix.dk/blog/post/19574
[2]. http://amix.dk/blog/post/19588
完整可运行的新闻搜索引擎Demo请看我的Github项目news_search_engine。
以下是系列博客:
Pingback: 和我一起构建搜索引擎(六)系统展示 | bitJoy
Pingback: 和我一起构建搜索引擎(三)构建索引 | bitJoy
Pingback: 和我一起构建搜索引擎(二)网络爬虫 | bitJoy
Pingback: 和我一起构建搜索引擎(一)简介 | bitJoy
Pingback: 和我一起构建搜索引擎(五)推荐阅读 | bitJoy
Pingback: 和我一起构建搜索引擎(七)总结展望 | bitJoy
Pingback: 和我一起构建搜索引擎(八)更新爬虫&修改打分&线上部署 | bitJoy