今天我们介绍如何使用CNN解决NLP问题。截止目前,我们学习了很多RNN模型来解决NLP问题,由于NLP是序列的问题,使用RNN这种循环神经网络是很符合直觉的,而且也取得了不错的效果。但是,由于RNN速度较慢,而且梯度消失问题比较严重,人们就想借用CV领域的CNN,看是否能解决NLP的问题。
我们在之前的博客中已经详细介绍过卷积神经网络CNN,这里不再详细介绍。下面我们以一篇paper中使用CNN对句子进行情感分类为例,简要介绍下怎样将CNN应用到NLP中。

今天我们介绍如何使用CNN解决NLP问题。截止目前,我们学习了很多RNN模型来解决NLP问题,由于NLP是序列的问题,使用RNN这种循环神经网络是很符合直觉的,而且也取得了不错的效果。但是,由于RNN速度较慢,而且梯度消失问题比较严重,人们就想借用CV领域的CNN,看是否能解决NLP的问题。
我们在之前的博客中已经详细介绍过卷积神经网络CNN,这里不再详细介绍。下面我们以一篇paper中使用CNN对句子进行情感分类为例,简要介绍下怎样将CNN应用到NLP中。
这节课的内容比较简单,是问答系统(Question Answering, QA)的入门介绍。
首先,为什么需要QA?目前各大搜索引擎对于一个查询,给出的都是一个结果列表。但是很多查询是一个问题,答案也往往比较确定,比如“现任美国总统是谁?”,此时,返回一堆结果列表就显得太过啰嗦了,尤其是在手机等移动设备上搜索时,简单的给出回答也许会更好一些。另一方面,智能手机上的助手如Siri、Google Now之类的,用户期望的也是简洁的答案,而不是一堆网页列表。
QA系统的组成主要有两个部分,一部分是根据问题检索到相关的文档,这部分是传统的信息检索的内容;另一部分是对检索到的文档进行阅读理解,抽取出能回答问题的答案,这部分就是本文要介绍的QA系统。
QA的历史可追溯到上世纪七十年代,但真正取得突破性进展也就是最近几年。2015/2016年,几个大规模QA标注数据集的发表,极大的推动了这个领域的发展。这其中比较有名的数据集是斯坦福大学发布的Stanford Question Answering Dataset (SQuAD)。

今天介绍另一个NLP任务——机器翻译,以及神经网络机器翻译模型seq2seq和一个改进技巧attention。
机器翻译最早可追溯至1950s,由于冷战的需要,美国开始研制由俄语到英语的翻译机器。当时的机器翻译很简单,就是自动从词典中把对应的词逐个翻译出来。
后来在1990s~2010s,统计机器翻译(Statistical Machine Translation, SMT)大行其道。假设源语言是法语$x$,目标语言是英语$y$,机器翻译的目标就是寻找$y$,使得$P(y|x)$最大,也就是下图的公式。进一步,通过贝叶斯公式可拆分成两个概率的乘积:其中$P(y)$就是之前介绍过的语言模型,最简单的可以用n-gram的方法;$P(x|y)$是由目标语言到源语言的翻译模型。为什么要把$P(y|x)$的求解变成$P(x|y)*P(y)$?逐个击破的意思,$P(x|y)$专注于翻译模型,翻译好局部的短语或者单词;而$P(y)$就是之前学习的语言模型,用来学习整个句子$y$的概率,专注于翻译出来的句子从整体上看起来更加通顺、符合语法与逻辑。所以问题就转化为怎样求解$P(x|y)$。

梯度消失
今天介绍RNN的梯度消失问题以及为了解决这个问题引出的RNN变种,如LSTM何GRU。
在上一篇博客中,通过公式推导,我们已经解释了RNN为什么容易产生梯度消失或梯度爆炸的问题,核心问题就是RNN在不同时间步使用共享参数$W$,导致$t+n$时刻的损失对$t$时刻的参数的偏导数存在$W$的指数形式,一旦$W$很小或很大就会导致梯度消失或梯度爆炸的问题。下图形象的显示了梯度消失的问题,即梯度不断反传,梯度不断变小(箭头不断变小)。

今天要介绍一个新的NLP任务——语言模型(Language Modeling, LM),以及用来训练语言模型的一类新的神经网络——循环神经网络(Recurrent Neural Networks, RNNs)。
语言模型就是预测一个句子中下一个词的概率分布。如下图所示,假设给定一个句子前缀是the students opened their,语言模型预测这个句子片段下一个词是books、laptops、exams、minds或者其他任意一个词的概率。形式化表示就是计算概率
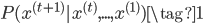
$x^{(t+1)}$表示第$t+1$个位置(时刻)的词是$x$,$x$可以是词典$V$中的任意一个词。

Dependency Parsing是指对句子进行语法分析并画出句子成分的依赖关系,比如对于句子“She saw the video lecture”,首先可以分析出主语、谓语、宾语等句子成分;其次可以分析出依赖关系,比如saw依赖于She等。这就是句法分析。完成句法分析的算法被称为句法分析器parser,一个parser的性能可以用UAS和LAS来衡量,UAS就是parse出来的依赖关系对比正确依赖关系的正确率,LAS就是句子成分分析的正确率。

这篇博客把1.15和1.17两次课内容合并到一起,因为两次课的内容都是BP及公式推导,和之前的Neural Networks and Deep Learning(二)BP网络内容基本相同,这里不再赘述。下面主要列一些需要注意的知识点。
使用神经网络进行表示学习,不用输入的x直接预测输出,而是加一个中间层(图中橙色神经元),让中间层对输入层做一定的变换,然后中间层负责预测输出是什么。那么中间层能学到输入层的特征,相当于表示学习,自动学习特征。对于word2vec,中间层就是词向量。

这一讲是上一讲的补充,内容比较零碎,包括:Word2vec回顾、优化、基于统计的词向量、GloVe、词向量评价、词义等,前两个内容没必要再介绍了,下面逐一介绍后四个内容。
基于统计的词向量
词向量的目的就是希望通过低维稠密向量来表示词的含义,而词的分布式语义表示方法认为词的含义由其上下文语境决定。Word2vec把中心词和临近词抽取出来,通过预测的方式训练得到词向量。在Word2vec之前,传统的方式通过统计词的共现性来得到词向量,即一个词的词向量表示为其临近词出现的频率,如果两个词的含义很相近,则其临近词分布会比较像,得到的词向量也比较像。其具体计算过程在第一次作业中有详细的描述,这里再简单回顾如下。
假设一个语料库中包含三个句子,共有8个特异词(包括点号),对于每个词,统计其前后一个词的词频(临近窗口为1),由此能得到一个8×8的对称矩阵,其每一行(或每一列)表示该词的词向量。比如对于like这个词,在三个句子中,其左右共出现2次I,1次deep和1次NLP,所以like对应的词向量中,I、deep和NLP维的值分别为2,1,1。

今天开始介绍大名鼎鼎的NLP网课Stanford-CS224N。第一讲内容为课程简介和词向量。
词向量即用来表示这个词的含义的向量。早期的NLP常用one-hot编码来表示词向量,假如词典中共有10000个词,则这个one-hot向量长度就是10000,该词在词典中所处位置对应的值为1,其他值为0。
one-hot表示方法虽然简单,但其有诸多缺点:1. 词典中的词是不断增多的,比如英语,通过对原有的词增加前缀和后缀,可以变换出很多不同的词,one-hot编码会导致向量维度非常大,且每个向量是稀疏的;2. 不同词的one-hot编码向量是垂直的,在向量空间中无法表示近似关系,即使两个含义相近的词,它们的词向量点积也为0。
既然one-hot编码有这么多缺点,那我们就换一种编码,one-hot是高维稀疏向量,那新的编码就改用低维稠密向量,这样就解决了上述问题,那么怎样得到一个词的低维稠密的词向量呢?这就是word2vec算法。
Continue reading相信很多学CS的同学之前都没听说过“蛋白质结构预测”这个问题,直到2018年12月初,一则劲爆消息瞬间引爆了CSer的朋友圈,那就是Google Deepmind团队开发的AlphaFold一举拿下当年的CASP比赛冠军,而且远远甩开了第二名。我当时就转载过类似的公众号文章,大家可以阅读并想象当时朋友圈的欢呼声:阿尔法狗再下一城 | 蛋白结构预测AlphaFold大胜传统人类模型。
当时,很多同学也转载过类似的文章,但其实很少有人真正明白“蛋白质结构预测”这个问题是什么,它的难度有多大,CASP是个什么比赛,以及AlphaFold的内部原理是什么。当然,对于这一连串的问题,我当时也是懵逼的。不过自己好歹也是个跟蛋白质有关的PhD,如此热点事件,自然是要关注的。不过之后一直没时间,直到今年相关顶级文章再次爆出,我就借着准备文献讲评的机会了解了相关的知识,在这里跟大家分享一下。
