构建好倒排索引之后,就可以开始检索了。
检索模型有很多,比如向量空间模型、概率模型、语言模型等。其中最有名的、检索效果最好的是基于概率的BM25模型。
Continue reading目前正是所谓的“大数据”时代,数据量多到难以计数,怎样结构化的存储以便于分析计算,是当前的一大难题。上一篇博客我们简单抓取了1000个搜狐新闻数据,搜索的过程就是从这1000个新闻中找出和关键词相关的新闻来,那么怎样快速搜索呢,总不可能依次打开xml文件一个字一个字的找吧,这时就需要借助倒排索引这个强大的数据结构。 Continue reading
网络爬虫又称网络蜘蛛、Web采集器等,它是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
我们在设计网络爬虫的时候需要注意两点:
鲁棒性。Web中有些服务器会制造采集器陷阱(spider traps),这些陷阱服务器实际上是Web页面的生成器,它能在某个域下生成无数网页,从而使采集器陷入到一个无限的采集循环中去。采集器必须能从这些陷阱中跳出来。当然,这些陷阱倒不一定都是恶意的,有时可能是网站设计疏忽所导致的结果。
礼貌性。Web服务器具有一些隐式或显式的政策来控制采集器访问它们的频率。设计采集器时必须要遵守这些代表礼貌性的访问政策。 Continue reading
我们上网用得最多的一项服务应该是搜索,不管大事小情,都喜欢百度一下或谷歌一下,那么百度和谷歌是怎样从浩瀚的网络世界中快速找到你想要的信息呢,这就是搜索引擎的艺术,属于信息检索的范畴。
这学期学习了《现代信息检索》课程,使用的是Stanford的教材Introduction to Information Retrieval,网上有电子版,大家可以参考。 Continue reading
安装WIN10一个月以来,校园有线网经常间歇性断网,通常是20分钟不到就断了,需要重启或者把有线连接关闭再打开才可以。在微博上问过微软客服也无果,后来Google到某国外的解决办法,现记录如下。 Continue reading
进入研究生生涯完成的第一个新生培训作业是“2.5亿个浮点数的外部排序算法”,前后折腾了将近一个月,结果是在i7处理器上,限制512MB内存,排序用时250秒左右。
这个作业的常规思路大部分人都能想到,按块读取文件->atof转换为double->内部快速排序或基数排序->dtoa转换为char*->按块写入文件。这里面中间的三个过程都很耗时,特别是atof和dtoa,因为精度只要求保留9位小数,所以可以自己实现atof和dtoa来加速,也可以使用多线程加速。
整个作业都是基于对IEEE754浮点数的深刻理解展开的,所以下面详细讲解浮点数的一些知识。
IEEE754双精度浮点数
目前大多数CPU内浮点数的表示都遵循IEEE754标准,IEEE754双精度浮点数(double)表示如下图所示。
![IEEE754 double在内存中的形式[1]](https://upload.wikimedia.org/wikipedia/commons/a/a9/IEEE_754_Double_Floating_Point_Format.svg)
去年暑假在北大计算所实习的时候,任务之一就是批量下载百度图片。当时没学python,用c#实现了一个简易版本的批量下载器,如下图。
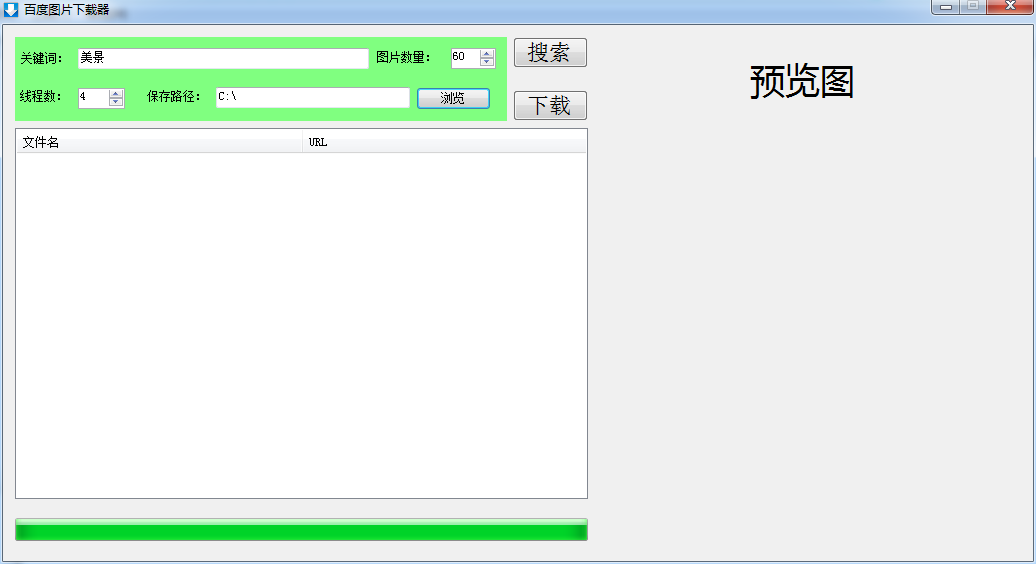
C#版本百度图片批量下载器(抓的是百度的wap站点,现在好像不能用了)
当时“时间紧,任务重“,既没仔细研究百度图片API,也没处理好界面线程阻塞的问题。这个问题其实很有意思,趁着暑假在家,实现了一个比较完美的python版本,先上效果图。
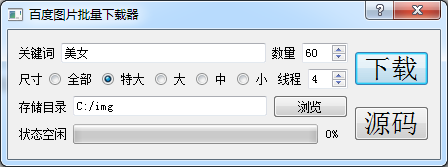
python3版本百度图片批量下载器
在上一题POJ Problem 1837: Balance中,我们曾讲到,如果只有两个挂钩,问题会好办得多,就拿题目给的样例数据来说:
Sample Input
2 4
-2 3
3 4 5 8
Sample Output
2
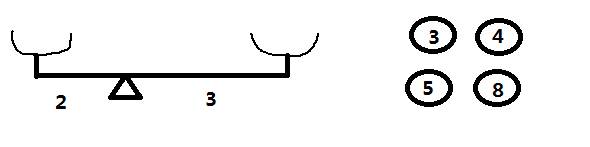
如上图所示,给定重量为3,4,5,8的砝码,放在一个左右臂长分别为2和3的天平上,要使天平平衡,问有多少种方法。 Continue reading
一、第一次使用Github的步骤:
1. 在这个页面中填写Repo名称
2. 不要勾选Initialize this repository with a README
3. 点击Create repository
4. 在本地使用Git命令行工具进入到和第1步填写Repo相同名称的文件夹中(此文件夹中已包含你要push到Github上的内容),执行以下几个命令:
git init touch README.md #optional git add . git commit -m 'your comment' git remote add origin https://github.com/UserName/RepoName git push origin master
5. 如果你在第2步中勾选了Initialize this repository with a README,那么在第4步中省略touch README.md并且在git add .之前,执行第5行代码,然后git pull origin master将远端(remote)的内容pull到本地
6. 关于Git命令中的fetch和pull的区别,请看这篇博文
7. 关于Git bash和Github的连接,请看这篇博文
二、Git命令中fetch和pull的区别(转载)
Git中从远程的分支获取最新的版本到本地有这样2个命令:
1. git fetch:相当于是从远程获取最新版本到本地,不会自动merge
git fetch origin master git log -p master..origin/master git merge origin/master
以上命令的含义:首先从远程的origin的master主分支下载最新的版本到origin/master分支上,然后比较本地的master分支和origin/master分支的差别,最后进行合并。
上述过程其实可以用以下更清晰的方式来进行:
git fetch origin master:tmp git diff tmp git merge tmp
从远程获取最新的版本到本地的test分支上,之后再进行比较合并。
2. git pull:相当于是从远程获取最新版本并merge到本地
git pull origin master
上述命令其实相当于git fetch + git merge。
在实际使用中,git fetch更安全一些,因为在merge前,我们可以查看更新情况,然后再决定是否合并。